
Neural Networks From Ground Up
Saw and amazing video by 3Blue1Brown. Where he introduces neural neyworks not as a black box but each neuron as a function which maps the input to the output.
1 - Intro
Previously researchers used to sigmoid function as an activation function which apparently gave poor performance nowadays most researchers use RELU.
The transformation in simple form is written by
a(1) = RELU(W*a(0) + B)
where:
W = Weight Matrix
B = Bias matrix
2 - CostFunction and Back Propagation
Here we learn about the cost function which calculates how well an algorithm is doing. And use it to give feedaback to our network.
3 - Working of Back Propagation
In the second video we learn about the structure of neural and network and how it is intialised. Also how the cost function is used to nudge the weights and biases to reach the local minima using the negative gradient descent (equivalent to slope on an 2D plane). In practice we use Schotastic Gradient Descent (SGD)
4 - Back Propagation Calaculus
Here we dwell deep into the math of calculating the SGD using calculus. I might need to re-learn calculus to completely comphrend this.
The final formula for single neuron:
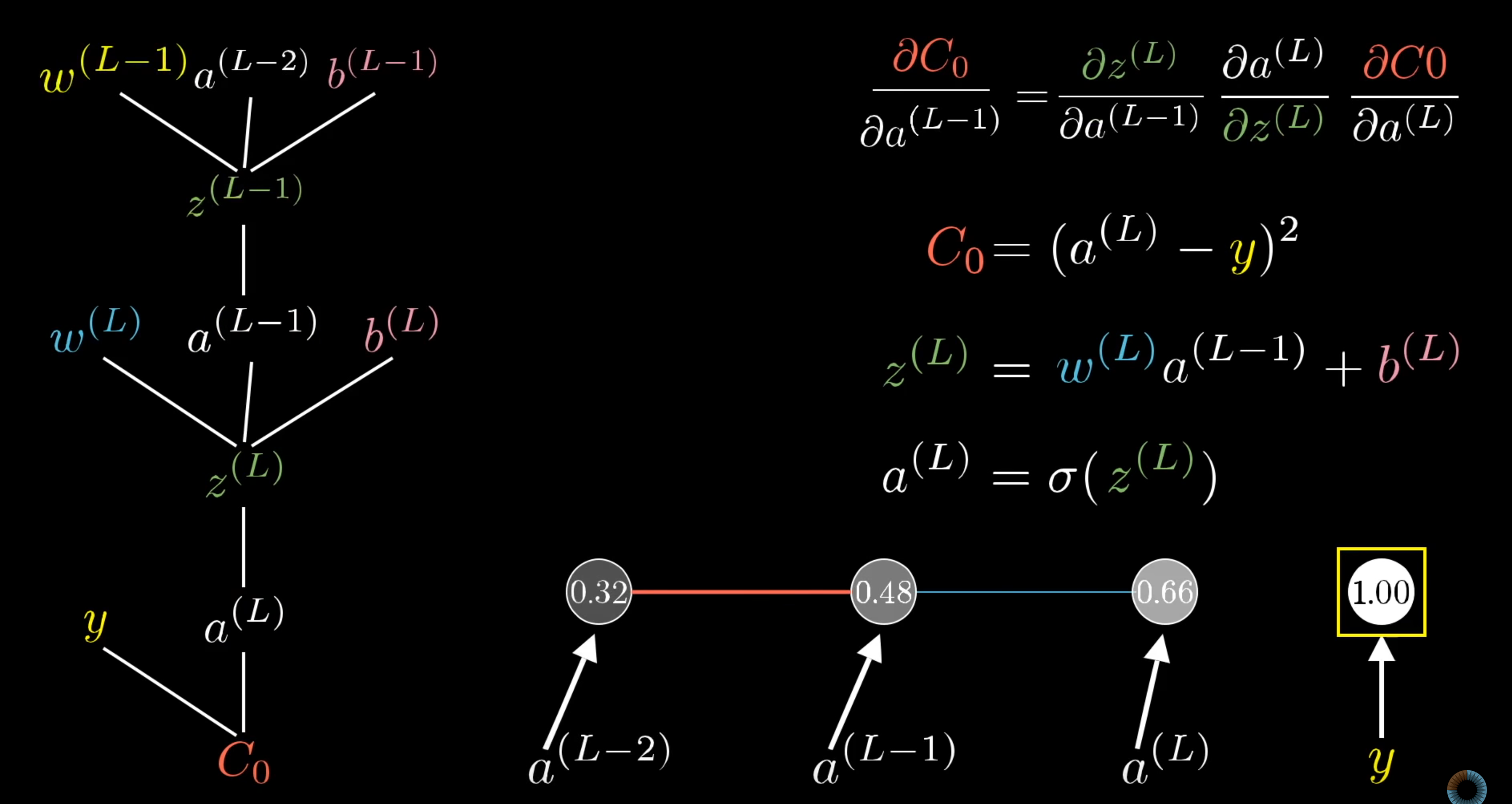
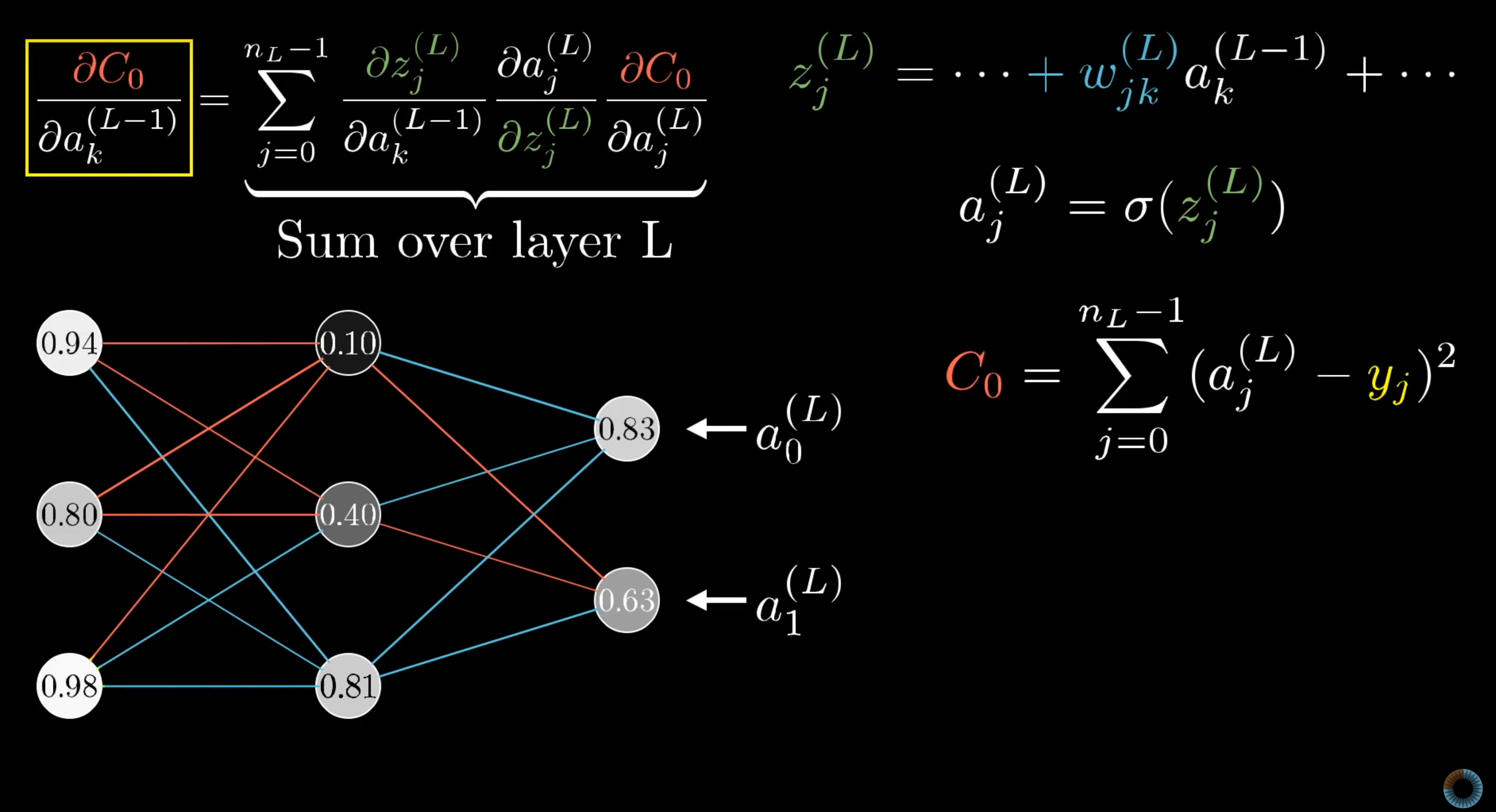
Formula for ‘n’ neurons:
Source:
Youtube Link